
DATE2025.07.19 #Press Releases
ディープラーニングに潜む普遍法則を発見
—— ディープニューラルネットワークを支配する「物理」 ——
発表のポイント
- ディープニューラルネットワークの信号伝搬過程に普遍的な法則が見られることを発見した。
- 普遍的な法則を足掛かりに、ディープラーニングの統一的な理解が可能になる。
- ディープラーニング設計への応用のほか、より広範な知的情報処理系の理解にも繋がる。
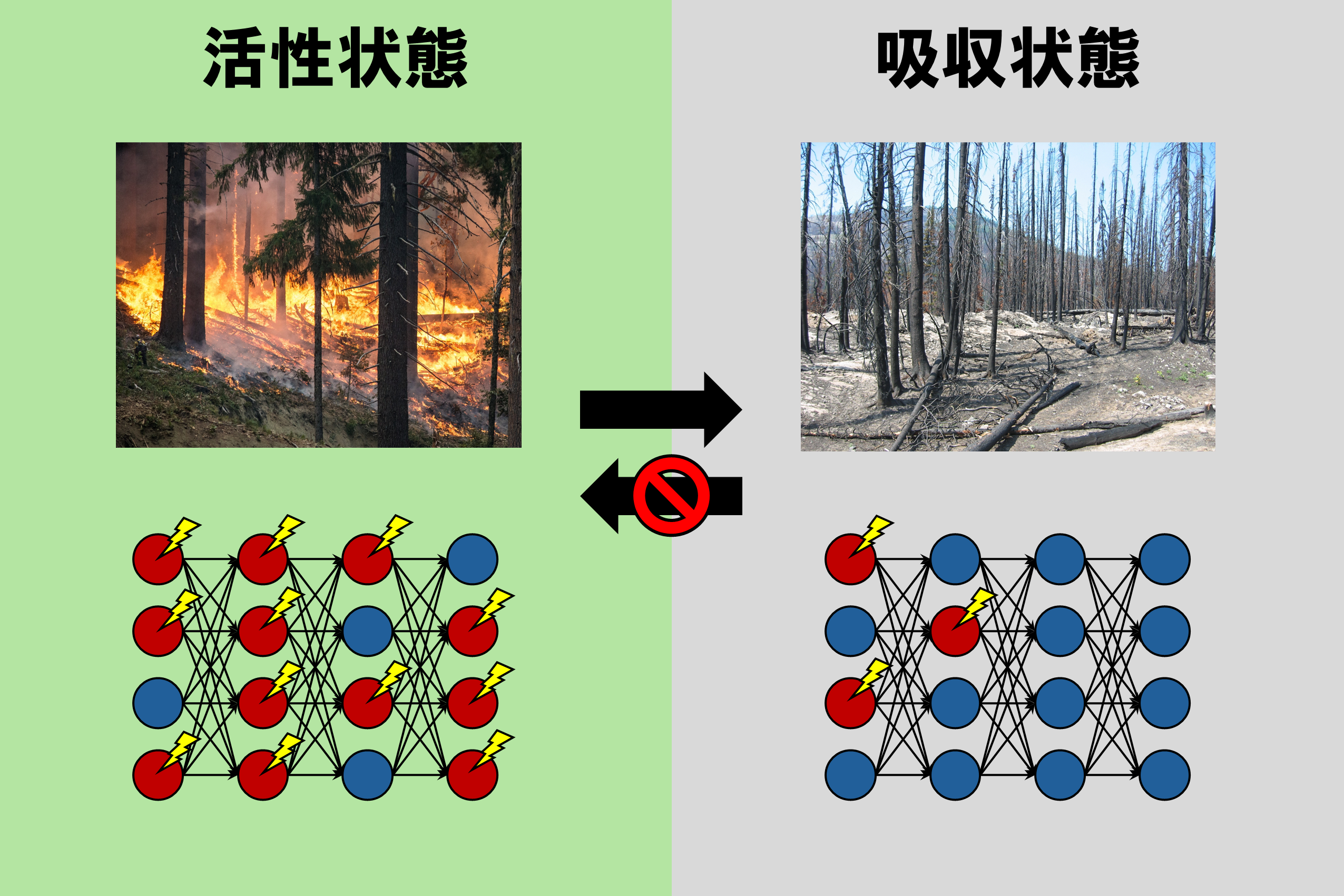
森林火災(上)と、ディープニューラルネットワークにおける人工ニューロンの活動(下)の類似性。
発表概要
東京大学大学院理学系研究科の玉井敬一特任研究員、大久保毅特任准教授、藤堂眞治教授、および株式会社アイシンの張潘(チュオンファン)チュオンズイプロジェクトマネージャー、名取直毅チーフプロジェクトジェネラルマネージャー(当時)らによる研究グループ(以下「本グループ」)は、ディープラーニングに普遍的な法則が見られることを発見しました。
本研究では、ディープニューラルネットワーク(注1) の信号伝搬過程と統計物理学における「吸収状態転移」(後述)の対応関係の確立に成功し、対応関係がディープラーニングに対して与える示唆を明らかにしました。ディープラーニングの統一的な理解に貢献する成果であり、ディープラーニングの系統的な設計に役立つだけでなく、神経科学や計算科学などといった周辺分野の知見と繋がることで、知的情報処理に対する理解の進展が期待されます。
本成果は、2025年7月18日(米国東部夏時間)に米国科学誌「Physical Review Research」にて公開されました。
発表内容
ディープラーニングに基づいた人工知能は、いまや日常生活に溶け込みつつあるほどの急速な進化を遂げています。一方、ディープラーニングの土台となるディープニューラルネットワークが働く仕組みの解明は依然として難問です。ディープニューラルネットワークは時に一兆個にも及ぶ膨大な数のパラメータから成り、個々のパラメータの意味付けが困難であることが、見通しの良い理解を妨げていました。本研究は、パラメータの多さを逆手に取って、ミクロな性質を用いてマクロな性質を研究する統計物理学の枠組に落とし込むことで、普遍的な法則を発見したものです。
本研究の要は、ディープニューラルネットワークの動作の本質を抜き出し、研究の蓄積がある問題設定に対応づけることです。ディープニューラルネットワークの信号伝搬過程は、ふたつの相反する過程のせめぎあいで成り立っています。たとえば、ニューロンがReLU関数(注2) を活性化関数に持つ場合(注3) の各ニューロンは、入力信号と閾値の比較で信号を奥の層に伝えるか止めるかを決めます(図1a)。ひとつの隠れ層内ですべてのニューロンが信号を止めてしまうと、それより奥の層には信号が一切伝わらなくなります(図1b)。このような「一度落ちると抜け出せない『吸収状態』に落ちるかがせめぎあいで決まる」という状況は、森林火災や感染症などありふれており、「吸収状態転移」として統計物理学で研究されてきました。その中で見出されてきた普遍法則と同じものが初期化したディープニューラルネットワークの信号伝搬過程にも現れることを、理論解析とシミュレーションの両面から明らかにしました。
 図1:ディープニューラルネットワークと「吸収状態」の関係。a. ReLU関数を活性化関数に持つディープニューラルネットワークの信号伝搬過程。隣接する隠れ層のニューロンが矢印で繋がっており、各矢印に重みが割り当てられている。信号を奥の層に伝えているニューロンを赤で、止めているニューロンを青であらわしている。b. 信号伝搬の結果、ひとつ奥の隠れ層にあるすべてのニューロンが信号を止めることはあっても、入力信号を一切受けていないニューロンが信号をひとりでに発生させることはない。
図1:ディープニューラルネットワークと「吸収状態」の関係。a. ReLU関数を活性化関数に持つディープニューラルネットワークの信号伝搬過程。隣接する隠れ層のニューロンが矢印で繋がっており、各矢印に重みが割り当てられている。信号を奥の層に伝えているニューロンを赤で、止めているニューロンを青であらわしている。b. 信号伝搬の結果、ひとつ奥の隠れ層にあるすべてのニューロンが信号を止めることはあっても、入力信号を一切受けていないニューロンが信号をひとりでに発生させることはない。
「吸収状態転移」の普遍的な法則に基づく枠組みでは、ふたつの相の境界に設定されたネットワークの個性は、活性化関数や重みの分散から決まるスケール因子(注4) 表されます(図2a)。これがディープラーニングにどう影響するのかが自然な関心の的になります。本グループは、隠れ層の幅(注5) が無限に広いディープニューラルネットワークの訓練過程を記述するNeural Tangent Kernel(注6)と信号伝搬過程の法則を理論的に関連付けることで、スケール因子と深さの積が性能を左右することを明らかにしました(図2b)。一方、信号伝搬過程のシミュレーションから、スケール因子が大きいネットワークほど、より広い幅が性能発揮に必要なことを示唆する結果も得られており、幅と深さのトレードオフ関係が見てとれます。つまり、信号伝搬過程の法則を足掛かりにして、ディープラーニングにおける活性化関数、深さ、幅選択の関係性を統一的な視点で捉えられることを示しました。

図2 :ディープニューラルネットワークの「吸収状態転移」と学習の成否の関係。a. リーク付きReLU関数(注7)を活性化関数に用いた、隠れ層の幅が無限に広いディープニューラルネットワークの相図。リークの大きさが0の場合が通常のReLU関数、1の場合が恒等関数にそれぞれ対応する。ふたつの相の境界における信号伝搬過程を特徴づけるスケール因子κは、境界に沿ってリークを増やしていくと単調に減少する。b. 相の境界上にネットワークを設定した場合も、ディープラーニングの成否はリークの大きさと隠れ層数Lの双方に依存する。しかし、幅が無限の場合、スケール因子付き隠れ層数κLが同じなら結果はほとんど変わらない。
今後、普遍的な法則に基づいた具体的なディープラーニング設計手法の確立や、スキップ接続(注8)のような工夫が施されたディープニューラルネットワークに対する本枠組みの応用によって、より効率的な技術開発に繋がっていくものと考えられます。さらには量子機械学習(注9)アルゴリズムや脳・神経系とディープニューラルネットワークの共通点・相違点を整理することで、知的情報処理に対する理論的理解が加速することが期待されます。
発表者・研究者等情報
東京大学大学院理学系研究科
玉井 敬一 特任研究員、大久保 毅 特任准教授、藤堂 眞治 教授
株式会社アイシン
張潘(チュオンファン) チュオン ズイ プロジェクトマネージャー、
名取 直毅 チーフプロジェクトジェネラルマネージャー(当時、現・慶應義塾大学グローバルリサーチインスティテュート 特任教授)
関連リンク
論文情報
-
雑誌名 Physical Review Research 論文タイトル Universal scaling laws of absorbing phase transitions in artificial deep neural networks著者 Keiichi Tamai*, Tsuyoshi Okubo, Truong Vinh Truong Duy, Naotake Natori and Synge Todo (*責任著者) DOI番号 10.1103/jp61-6sp2
研究助成
本研究は、科研費「波動関数理論と量子アルゴリズムの融合(課題番号:JP23H03818)」、JST共創の場形成支援プログラム「量子ソフトウェアとHPC・シミュレーション技術の共創によるサスティナブル量子AI研究拠点(課題番号:JPMJPF2221)」、および東京大学大学院理学系研究科「量子ソフトウェア」寄付講座の支援により実施されました。
用語解説
注1 ディープニューラルネットワーク
脳・神経系の働きを模した数理的なモデル。各ニューロンは「重み」を介して繋がっており、他のニューロンから入力として受け取った信号の重み付き総和に対してバイアスを付加し、活性化関数による非線型な変換をかけてから出力として放出する。古典的なディープニューラルネットワークの場合、ニューロンが層状に配置されており、手前隣の層の各ニューロンから入力を受け取って奥隣の層のニューロンに向かって出力する(図1a)。ディープラーニングでは、正規乱数で初期化された重みやバイアスを訓練データに基づいて最適化していくことで、訓練データにある特徴の抽出を目指す。↑
注2 ReLU関数
入力値が0以上であれば入力をそのまま出力し、0未満であれば0を出力する関数。正規化線型関数(rectifier linear unit)ともいう。ディープニューラルネットワークの場合、ニューロンの出力が0であることが、信号が止まった状態に対応し、出力に割り当てられた重み(図1aの細矢印が対応)の如何を問わず次の層の入力には寄与しない。↑
注3 活性化関数の選択
ディープニューラルネットワークの活性化関数としては、閾値を持たず、入力に対して出力が飽和するような関数(たとえば誤差関数)が使われることもある。この場合も、入力信号の差異が伝播過程で減衰するか拡大するかのせめぎあいが発生し、差異が完全に消失した状態が「吸収状態」に対応するので、大筋に変更はない。↑
注4 スケール因子
対象を問わず成り立つ物理法則には、しばしば対象の個性を反映するスケール因子が付随する(たとえば、ニュートンの運動方程式における質量)。ディープニューラルネットワークの場合、スケール因子は入力信号の差異に対する敏感さを表し、大きいほど鋭敏に反応する。↑
注5 隠れ層の幅
隠れ層あたりのニューロンの数のこと。「無限に広い」とは、隠れ層あたりのニューロンの数が無限の極限を指す。↑
注6 Neural Tangent Kernel (NTK)
ディープニューラルネットワークへの入力のペアが与えられたとき、それぞれに対応する出力の、パラメータ(重み、バイアス)に関する勾配ベクトルの内積として定義される関数。カーネル法という機械学習手法に使われるカーネル関数の性質を満たすことからこのような名前がついている。隠れ層の幅が無限に広い場合は、パラメータ自体を正規乱数で初期化した場合であってもNTKの初期値からはランダム性が消失し、さらに訓練アルゴリズムの学習率(1ステップあたりにパラメータを変動させる幅)が十分小さければ訓練過程でも変動しない。この場合、カーネル法の研究で蓄積されたノウハウを直接利用できるようになり、訓練過程の解析が容易になる。↑
注7 リーク付きReLU関数
入力値が0未満の場合に、入力値に適当な係数(リーク)を掛けた値を出力するように定義が変更された、ReLU関数の変種。Leaky ReLU (LReLU)関数ともいう。リークが0の場合は通常のReLU関数に他ならず、1の場合は、入力値を無条件でそのまま出力する恒等関数となる。リーク付きの場合も、隠れ層のニューロンからの出力がすべて0の状態は「吸収状態」に対応し、重みの分散が十分小さいときは、隠れ層を伝わるにつれ信号が減衰していくのが見られる。↑
注8 スキップ接続
ディープニューラルネットワークにおいて、隣よりも奥の隠れ層にあるニューロンと直接繋ぐこと。学習の安定化および特徴に関する情報伝搬の効率化に有用だといわれている。↑
注9 量子機械学習
量子力学の原理を使って、機械学習をより高速に、効率よく行う技術のこと。↑